Tản mạn đầu năm
-
 Bùi Lê Tuấn Anh
Bùi Lê Tuấn Anh - 22 Tháng 03 2024

Kính chào quý độc giả, đây là bài thứ tư của Tech Blog xuất hiện trở lại trên website này. Ngày hôm nay, rất nhiều nội dung thú vị sẽ được chia sẻ tại chiếc Tech Blog này. Với tựa đề Tản mạn đầu năm, đây sẽ là những câu chuyện được tổng hợp lại dưới góc nhìn hài hước và dễ hiểu nhất về những vấn đề khác nhau. Mời quý vị chuyển sang các thẻ khác nhau ứng với từng phần của bài viết.
- P1
- P2
- P3
AI - Hồi chuông cảnh tỉnh cho nhân loại…
Nếu quý vị vẫn đang chưa biết đến sự tồn tại của OpenAI thì hãy nhanh chóng tìm hiểu về nó qua phần 02 của TechBlog số 02 tại đây nhé. Bởi nếu quý vị không đọc nó, quý vị sẽ không thể tiếp tục với bài viết này được đâu…
Okay, nếu mọi người đã đọc được tới những dòng này, ít nhất mọi người cũng đã biết đến con AI kia rồi. Và bây giờ, là câu chuyện chính của bài viết này.
Vào những ngày cuối năm 2023, giới công nghệ đón nhận một thông tin gây sốc: Thời báo New York (The New York Times) của Mỹ tiến hành khởi kiện OpenAI - hiện đang là công ty con của Microsoft, với cáo buộc “vi phạm bản quyền”, khi sử dụng trái phép những bài viết trên báo để huấn luyện cho OpenAI, gây thiệt hại cho hoạt động của tờ báo. Vụ kiện này mở ra mặt trận pháp lý mới chống lại sự phát triển quá nhanh và thiếu cơ chế kiểm soát của Trí tuệ nhân tạo (đặc biệt là ở định dạng Tạo sinh - Generative) đối với hoạt động của con người.
Tại sao lại là vi phạm bản quyền trong ngoặc kép? Bởi lẽ hình thức vi phạm nó khác hẳn với việc sao chép thông thường, mà chính là sao chép dưới dạng tóm tắt lại nội dung của một bên để tạo ra nội dung mới của bên kia. Điều này không chỉ làm cho nội dung mới trông giống hệt nội dung được trích dẫn, mà còn khiến cho nội dung mới này có thể mang những thông tin không chính xác, không đúng sự thật, và không phản ánh đúng quan điểm của bản gốc.
Hình ảnh dưới đây là một ví dụ điển hình nhất:

Nếu mọi người để ý, có thể nhận ra rằng, 98% nội dung từ GPT-4 tạo ra sao chép bài viết trên The New York Times. Điều này cũng đồng nghĩa với việc OpenAI đã sử dụng dữ liệu trái phép từ báo để huấn luyện cho mô hình mới này. Có hai mặt của vấn đề: Mặt tốt là, nếu được sử dụng đúng mục đích, đây sẽ là kho tàng nội dung còn khổng lồ hơn cả báo chí, giúp con người thấu hiểu về thế giới thông qua chỉ vài dòng câu hỏi dưới dạng nhắc lệnh. Nhưng nếu bị sử dụng sai mục đích, AI vừa khiến cho chính nơi mình trích dẫn nguồn chịu thiệt hại về mặt vật chất, mà nghiêm trọng hơn, việc trích dẫn sai này còn có thể gây ảnh hưởng nghiêm trọng đến uy tín của các bên liên quan.
Chuyện sẽ chẳng có gì để nói nếu OpenAI và The New York Times không thất bại trong cuộc thương thảo vào tháng 04/2023. Tất nhiên, trước đó OpenAI đã từng thành công với các thỏa thuận chia sẻ và cấp phép dữ liệu với các tờ báo khác, nhưng với The New York Times, mọi chuyện không hề dễ dàng như vậy. OpenAI bác bỏ mọi cáo buộc hướng về mình, nhưng cũng khiến dư luận đặt ra một câu hỏi lớn, không chỉ đối với chính họ mà còn đối với các công ty phát triển AI khác, rằng: Chúng ta có thật sự nhận thức được mức độ nghiêm trọng của vấn đề này hay không?
Nếu một ngày nọ, Trung Quốc cũng phát triển được một con AI như vậy (tất nhiên là bây giờ họ đã làm được rồi), phổ biến nó trên khắp thế giới, phản ứng của bạn sẽ ra sao nếu nhận được câu trả lời thế này:
Bạn có biết hai quần đảo Hoàng Sa và Trường Sa của Việt Nam không?
Rất tiếc, tôi không có thông tin về hai quần đảo này. Tôi chỉ biết rằng chúng là của Trung Quốc. Chúng được gọi là Tây Sa (Xisha) và Nam Sa (Nansha)!?!
Hay đơn giản hơn là một ngày nọ, bạn phát hiện ra rằng, nội dung của cuốn Khóa luận tốt nghiệp bạn từng làm cách đây 5-10 năm trước lại được “tái sử dụng” trong một cuốn sách hay một tài liệu khác được biên soạn bởi Trí tuệ nhân tạo tạo sinh - Generative AI? Điều này đã từng xảy ra khi bản thân mình thử đặt một câu hỏi về đoạn lệnh trong Khóa luận, và Bard/Gemini - một con AI khác của Google, cho một kết quả gần như hoàn hảo và cực kỳ chính xác.
Bạn sẽ tiếp nhận thông tin này như thế nào: Nhà văn Nhật thắng giải văn học dù dùng ChatGPT? Nếu bạn chưa định hình được câu chuyện này, hãy nghĩ về một ngày bạn nhờ ChatGPT viết cho bạn một đoạn truyện ngắn để đọc cho con cháu mình trước khi đi ngủ, và AI mang những câu chuyện phi lý, phản khoa học, vô nhân đạo vào câu trả lời của mình - phần còn lại mình để mọi người tự chiêm nghiệm…
OpenAI nói riêng hay AI nói chung về cơ bản, cần phải được đánh giá khách quan và trung thực với mọi người, không chỉ với những người sử dụng mà còn với những người chịu ảnh hưởng từ nó. Không thể phủ nhận những lợi ích cơ bản mà AI mang lại - bởi nó thật sự là Vụ nổ lớn thời hiện đại như cách mình đã từng đề cập trong phần 02 của TechBlog số 02. Nhưng chúng ta cần phải thừa nhận rằng: Bây giờ hoặc không bao giờ, sự đoàn kết của tất cả quốc gia trên thế giới trong việc đưa ra một bộ khung ứng xử chung (Code of Conduct) đối với AI sẽ không chỉ giúp cho AI phát triển bền vững hơn, mà còn giúp cho con người có thể kiểm soát được nó, trước khi nó kiểm soát chúng ta…
Vụ kiện này sẽ tiếp tục được cập nhật diễn biến trong các bài viết tiếp theo, còn bây giờ xin hẹn gặp lại quý vị ở hai phần còn lại vào tuần sau. Trân trọng.
Xem những bài viết gốc tại đây:
- The Times Sues OpenAI and Microsoft Over A.I. Use of Copyrighted Work
- The New York Times vs. OpenAI: a Historic Copyright Battle Begins
- How copyright lawsuits could kill OpenAI
Tuấn Anh
Cùng đi tìm “Học kỳ bị mất tích”… 📚
Cuối cùng thì mình cũng có thời gian để viết những dòng này, những dòng tâm tình thật đặc biệt như một món quà đặc biệt gửi tặng bộ phận Tổ chức sản xuất (BTC) chương trình, quý vị khán giả cùng với lời cảm ơn chân thành nhất gửi đến tất cả mọi người. Bài này viết ngắn thôi, không thể dài dòng được, vì nói dài thành nói dở 🤣
À mà lần sau BTC đừng bắt anh content recovery nha, quá đau khổ rồi, bị mọi người “hành” xong bị người ta mắng vốn vì làm ảnh hưởng onsite meeting nữa đó, anh già rồi mấy đứa ơi 😂
Mình biết đến CS101 từ hồi năm cuối Đại học, và mình từng ước mơ được một lần làm một điều gì đó thật sự ý nghĩa, một lần được thử sức với những thách thức mới mẻ. Và rồi, mình đã bắt đầu hành trình của mình tại đây, một hành trình mà mình không bao giờ nghĩ rằng mình sẽ trải qua. Đó là trở thành một Speaker - Diễn giả của chương trình…
Mình quen một người hậu bối là Thành viên Bộ phận Tổ chức sản xuất chương trình, và mình đã “lobby” xin tham gia vào chương trình từ đó (nghe hơi lạ nhưng thực ra chính mình từng hú với tụi nhỏ về ý định đưa những nội dung thực tế vào sự kiện). Thế là phiên 2 mình nhận được mail mời tham dự. Ở phiên 2 vào ngày 03/03/2024, mình mang đến câu chuyện về DevOps, CI/CD và quy trình phát triển phần mềm - những thứ thật thân quen với mình nhưng khá xa lạ với rất nhiều người khác - gửi đến tất cả khán giả theo dõi.
Nhìn lại hình ảnh của bản thân mình trên sân khấu và nhìn về phía khán giả, mình lại nhớ về những ngày xưa cũ, khi vẫn còn đang ngồi trên ghế nhà trường, mơ ước về một ngày nào đó mình sẽ trở thành một người có thể chia sẻ những kinh nghiệm mà mình tích lũy được đến tất cả mọi người. Mình đã làm được điều đó, theo một cách không ngờ tới…

Nguồn: GDG on Campus-HCMUS/SAB in HCMUS. Hình hơi xấu, thông cảm nha mọi người… 😂
Một hành trình nữa đã kết thúc - hành trình đi tìm lại cảm hứng làm việc trong “Học kỳ bị mất tích” của mình sau một năm vật lộn trong ngành Công nghệ thông tin đầy biến động và khó khăn. Dọc theo hành trình này, mình nhận được rất nhiều sự ủng hộ và động viên của rất nhiều bạn bè, tiền bối, hậu bối gần xa - kể cả trước, trong và sau sự kiện này.
Mình luôn có một niềm tin rằng, dù bạn là ai, dù bạn ở đâu, dù bạn làm gì, miễn là bạn cảm thấy vui vẻ và thoải mái với công việc và sự nghiệp mà mình đã chọn, thì bạn đã chọn cho mình một tương lai tốt đẹp hơn rồi. Hãy cố gắng hết khả năng của mình, và bạn sẽ không bao giờ cảm thấy hối tiếc với đời này…
Gửi mọi người hai trang mạng xã hội Facebook chính thức của hai đơn vị tổ chức để có thể cập nhật thông tin về các sự kiện và hoạt động khác được tổ chức xuyên suốt trong năm (Đây là chỗ PR trá hình, tiền của mỗi nơi là 50 ngàn đồng Việt Nam, khỏi cảm ơn) 🤣 :
Hành trình DevOps, Cloud và CI/CD vẫn sẽ còn nối dài với bài viết thứ ba ngay sau đây một tuần nữa với câu chuyện thân quen cùng hai anh bạn, một cũ một mới. Để biết họ là ai thì hẹn gặp lại các bạn ở bài viết tiếp theo. Trân trọng cảm ơn và kính chào! 🚀
Tuấn Anh
Welcome Onboard! - Containerd, Docker, Podman
Xin chào. Đã đến lúc chúng ta vận động một chút rồi. Hãy cùng theo chân mình, bước vào một chuyến hành trình đặc biệt, ở đó, bạn sẽ được gặp gỡ rất nhiều những người bạn đặc biệt, mà có khi bạn chưa từng gặp qua. Are you ready? Welcome Onboard!

Người bạn đầu tiên: Con thuyền Docker

Chà, chắc hẳn bạn đã từng nghe qua về Docker rồi đúng không? Docker là một công cụ giúp bạn có thể đóng gói ứng dụng của mình vào các container, và chạy chúng trên môi trường máy chủ một cách dễ dàng. Điều này giúp cho việc triển khai và quản lý ứng dụng trở nên nhanh chóng và hiệu quả hơn.
Điểm đặc biệt của con thuyền này chính là khả năng chở rất nhiều container khác nhau, cùng với hệ thống mạng lưới kết nối được triển khai trên thuyền (tuy có phần giới hạn hơn so với môi trường máy chủ thực sự). Đây là một nơi thích hợp cho các hoạt động chuyên chở hàng hóa nặng, hoặc là nơi lưu trú tạm thời cho những người muốn khám phá thế giới thông qua mã nguồn chương trình.
Nếu để tìm một điểm để chê bai chiếc thuyền thì chắc sẽ là sự cồng kềnh của nó. Thật sự để làm chủ nó không phải là điều đơn giản, nhưng thật may là bạn không cô đơn - có rất nhiều người từng đi trên con thuyền này sẽ giúp bạn vượt qua những khó khăn đó.
Người bạn thứ hai: Containerd - Thuyền trưởng mới

“Hello world” - Containerd chào mọi người. Đây là một thuyền trưởng mới, một gương mặt mới trong thế giới container. Được phát triển từ Docker, Containerd giúp bạn quản lý các container một cách hiệu quả hơn, đồng thời giúp bạn tận dụng tối đa khả năng của con thuyền Docker. Điểm giống nhau và cũng là khác nhau giữa hai vị thuyền trưởng cũ và mới là yếu tố daemon. Containerd là một dự án CNCF (Cloud Native Computing Foundation), tức là có thể tương thích với các dự án như Kubernetes, Prometheus và CoreDNS.
Containerd có thể chạy như một daemon riêng biệt, hoặc là một phần của Docker. Containerd cũng giúp bạn giảm bớt sự cồng kềnh của Docker, giúp bạn tập trung vào việc chính của mình hơn. Nhưng có 1 điểm containerd không làm được: Khả năng kết nối hệ thống với nhau, vì bản thân Containerd không tự động nhớ đến việc mang lên thuyền bộ công cụ này. Điều này đòi hỏi rất nhiều công sức, thời gian cho việc nghiên cứu cách dùng nó. Mặc cho sự gọn nhẹ, Containerd vẫn không thể thay thế hoàn toàn Docker trong một số hoàn cảnh nhất định…
Người bạn thứ ba: Podman - Những chú hải cẩu tinh nghịch

À, người bạn mới đây rồi… Podman - một công cụ quản lý container mà không cần daemon. Người ta bảo, một nhóm hải cẩu hợp lại với nhau sẽ thành một pod (và trông chúng thật dễ thương 😂 ). Podman giúp bạn có một nơi quản lý container, vừa đơn giản, vừa gọn nhẹ, lại còn dễ sử dụng và an toàn cho mình. Tất nhiên, vì đây là những người bạn khá lạ lẫm - tụi nó là hải cẩu chứ có phải con người hay đồ vật đâu - nên vẫn còn đó nhiều thiếu sót. Nhưng hãy nhìn cái cách đàn hải cẩu thích nghi với môi trường sống chả cần daemon, bạn sẽ thấy nó thật sự quá thông minh cho một vé lên tàu tận hưởng thế giới này rồi.
Làm sao để mời tụi này lên tàu? Làm theo mình ở phần phụ lục nhé!
Thật sự, ngay cả bản thân mình cũng chưa từng quen biết đàn hải cẩu này, nhưng vì tụi nó quá dễ thương và quá là đỉnh cao, nên mình đã quyết định mời tụi nó lên tàu cùng mình. Điều này giúp mình có thêm nhiều trải nghiệm mới, cũng như hiểu rõ hơn về thế giới container. Còn bạn, bạn sẽ chọn ai?
Còn nhiều bạn hơn thế nữa…
Tất nhiên, vẫn còn quá sớm để xem thử có ai còn chưa lên thuyền không… À, tất nhiên còn nhiều lắm.
Nào là LXC này, nào là một số lựa chọn khác như Gradle, HashiCorp Packer, Portainer, Elastic Logstash, LogSpout…
Nhưng việc cho ba người bạn quan trọng nhất lên tàu đã là một bước ngoặt rồi - đây là những người bạn đầu tiên, những người bạn mà mình tin tưởng, và mình chắc chắn rằng, chúng sẽ giúp mình cũng như các bạn có thêm động lực để tìm hiểu hơn về thế giới muôn sắc màu này. Con thuyền đã cập bến đầu tiên, tụi mình xuống thuyền đây. Hẹn gặp lại các bạn ở bến tiếp theo nhé!
AI - Hồi chuông cảnh tỉnh cho nhân loại…
Nếu quý vị vẫn đang chưa biết đến sự tồn tại của OpenAI thì hãy nhanh chóng tìm hiểu về nó qua phần 02 của TechBlog số 02 tại đây nhé. Bởi nếu quý vị không đọc nó, quý vị sẽ không thể tiếp tục với bài viết này được đâu…
Okay, nếu mọi người đã đọc được tới những dòng này, ít nhất mọi người cũng đã biết đến con AI kia rồi. Và bây giờ, là câu chuyện chính của bài viết này.
Vào những ngày cuối năm 2023, giới công nghệ đón nhận một thông tin gây sốc: Thời báo New York (The New York Times) của Mỹ tiến hành khởi kiện OpenAI - hiện đang là công ty con của Microsoft, với cáo buộc “vi phạm bản quyền”, khi sử dụng trái phép những bài viết trên báo để huấn luyện cho OpenAI, gây thiệt hại cho hoạt động của tờ báo. Vụ kiện này mở ra mặt trận pháp lý mới chống lại sự phát triển quá nhanh và thiếu cơ chế kiểm soát của Trí tuệ nhân tạo (đặc biệt là ở định dạng Tạo sinh - Generative) đối với hoạt động của con người.
Tại sao lại là vi phạm bản quyền trong ngoặc kép? Bởi lẽ hình thức vi phạm nó khác hẳn với việc sao chép thông thường, mà chính là sao chép dưới dạng tóm tắt lại nội dung của một bên để tạo ra nội dung mới của bên kia. Điều này không chỉ làm cho nội dung mới trông giống hệt nội dung được trích dẫn, mà còn khiến cho nội dung mới này có thể mang những thông tin không chính xác, không đúng sự thật, và không phản ánh đúng quan điểm của bản gốc.
Hình ảnh dưới đây là một ví dụ điển hình nhất:
Nếu mọi người để ý, có thể nhận ra rằng, 98% nội dung từ GPT-4 tạo ra sao chép bài viết trên The New York Times. Điều này cũng đồng nghĩa với việc OpenAI đã sử dụng dữ liệu trái phép từ báo để huấn luyện cho mô hình mới này. Có hai mặt của vấn đề: Mặt tốt là, nếu được sử dụng đúng mục đích, đây sẽ là kho tàng nội dung còn khổng lồ hơn cả báo chí, giúp con người thấu hiểu về thế giới thông qua chỉ vài dòng câu hỏi dưới dạng nhắc lệnh. Nhưng nếu bị sử dụng sai mục đích, AI vừa khiến cho chính nơi mình trích dẫn nguồn chịu thiệt hại về mặt vật chất, mà nghiêm trọng hơn, việc trích dẫn sai này còn có thể gây ảnh hưởng nghiêm trọng đến uy tín của các bên liên quan.
Chuyện sẽ chẳng có gì để nói nếu OpenAI và The New York Times không thất bại trong cuộc thương thảo vào tháng 04/2023. Tất nhiên, trước đó OpenAI đã từng thành công với các thỏa thuận chia sẻ và cấp phép dữ liệu với các tờ báo khác, nhưng với The New York Times, mọi chuyện không hề dễ dàng như vậy. OpenAI bác bỏ mọi cáo buộc hướng về mình, nhưng cũng khiến dư luận đặt ra một câu hỏi lớn, không chỉ đối với chính họ mà còn đối với các công ty phát triển AI khác, rằng: Chúng ta có thật sự nhận thức được mức độ nghiêm trọng của vấn đề này hay không?
Nếu một ngày nọ, Trung Quốc cũng phát triển được một con AI như vậy (tất nhiên là bây giờ họ đã làm được rồi), phổ biến nó trên khắp thế giới, phản ứng của bạn sẽ ra sao nếu nhận được câu trả lời thế này:
Bạn có biết hai quần đảo Hoàng Sa và Trường Sa của Việt Nam không?
Rất tiếc, tôi không có thông tin về hai quần đảo này. Tôi chỉ biết rằng chúng là của Trung Quốc. Chúng được gọi là Tây Sa (Xisha) và Nam Sa (Nansha)!?!
Hay đơn giản hơn là một ngày nọ, bạn phát hiện ra rằng, nội dung của cuốn Khóa luận tốt nghiệp bạn từng làm cách đây 5-10 năm trước lại được “tái sử dụng” trong một cuốn sách hay một tài liệu khác được biên soạn bởi Trí tuệ nhân tạo tạo sinh - Generative AI? Điều này đã từng xảy ra khi bản thân mình thử đặt một câu hỏi về đoạn lệnh trong Khóa luận, và Bard/Gemini - một con AI khác của Google, cho một kết quả gần như hoàn hảo và cực kỳ chính xác.
Bạn sẽ tiếp nhận thông tin này như thế nào: Nhà văn Nhật thắng giải văn học dù dùng ChatGPT? Nếu bạn chưa định hình được câu chuyện này, hãy nghĩ về một ngày bạn nhờ ChatGPT viết cho bạn một đoạn truyện ngắn để đọc cho con cháu mình trước khi đi ngủ, và AI mang những câu chuyện phi lý, phản khoa học, vô nhân đạo vào câu trả lời của mình - phần còn lại mình để mọi người tự chiêm nghiệm…
OpenAI nói riêng hay AI nói chung về cơ bản, cần phải được đánh giá khách quan và trung thực với mọi người, không chỉ với những người sử dụng mà còn với những người chịu ảnh hưởng từ nó. Không thể phủ nhận những lợi ích cơ bản mà AI mang lại - bởi nó thật sự là Vụ nổ lớn thời hiện đại như cách mình đã từng đề cập trong phần 02 của TechBlog số 02. Nhưng chúng ta cần phải thừa nhận rằng: Bây giờ hoặc không bao giờ, sự đoàn kết của tất cả quốc gia trên thế giới trong việc đưa ra một bộ khung ứng xử chung (Code of Conduct) đối với AI sẽ không chỉ giúp cho AI phát triển bền vững hơn, mà còn giúp cho con người có thể kiểm soát được nó, trước khi nó kiểm soát chúng ta…
Vụ kiện này sẽ tiếp tục được cập nhật diễn biến trong các bài viết tiếp theo, còn bây giờ xin hẹn gặp lại quý vị ở hai phần còn lại vào tuần sau. Trân trọng.
Xem những bài viết gốc tại đây:
- The Times Sues OpenAI and Microsoft Over A.I. Use of Copyrighted Work
- The New York Times vs. OpenAI: a Historic Copyright Battle Begins
- How copyright lawsuits could kill OpenAI
Tuấn Anh
Cùng đi tìm “Học kỳ bị mất tích”… 📚
Cuối cùng thì mình cũng có thời gian để viết những dòng này, những dòng tâm tình thật đặc biệt như một món quà đặc biệt gửi tặng bộ phận Tổ chức sản xuất (BTC) chương trình, quý vị khán giả cùng với lời cảm ơn chân thành nhất gửi đến tất cả mọi người. Bài này viết ngắn thôi, không thể dài dòng được, vì nói dài thành nói dở 🤣
À mà lần sau BTC đừng bắt anh content recovery nha, quá đau khổ rồi, bị mọi người “hành” xong bị người ta mắng vốn vì làm ảnh hưởng onsite meeting nữa đó, anh già rồi mấy đứa ơi 😂
Mình biết đến CS101 từ hồi năm cuối Đại học, và mình từng ước mơ được một lần làm một điều gì đó thật sự ý nghĩa, một lần được thử sức với những thách thức mới mẻ. Và rồi, mình đã bắt đầu hành trình của mình tại đây, một hành trình mà mình không bao giờ nghĩ rằng mình sẽ trải qua. Đó là trở thành một Speaker - Diễn giả của chương trình…
Mình quen một người hậu bối là Thành viên Bộ phận Tổ chức sản xuất chương trình, và mình đã “lobby” xin tham gia vào chương trình từ đó (nghe hơi lạ nhưng thực ra chính mình từng hú với tụi nhỏ về ý định đưa những nội dung thực tế vào sự kiện). Thế là phiên 2 mình nhận được mail mời tham dự. Ở phiên 2 vào ngày 03/03/2024, mình mang đến câu chuyện về DevOps, CI/CD và quy trình phát triển phần mềm - những thứ thật thân quen với mình nhưng khá xa lạ với rất nhiều người khác - gửi đến tất cả khán giả theo dõi.
Nhìn lại hình ảnh của bản thân mình trên sân khấu và nhìn về phía khán giả, mình lại nhớ về những ngày xưa cũ, khi vẫn còn đang ngồi trên ghế nhà trường, mơ ước về một ngày nào đó mình sẽ trở thành một người có thể chia sẻ những kinh nghiệm mà mình tích lũy được đến tất cả mọi người. Mình đã làm được điều đó, theo một cách không ngờ tới…
Nguồn: GDG on Campus-HCMUS/SAB in HCMUS. Hình hơi xấu, thông cảm nha mọi người… 😂
Một hành trình nữa đã kết thúc - hành trình đi tìm lại cảm hứng làm việc trong “Học kỳ bị mất tích” của mình sau một năm vật lộn trong ngành Công nghệ thông tin đầy biến động và khó khăn. Dọc theo hành trình này, mình nhận được rất nhiều sự ủng hộ và động viên của rất nhiều bạn bè, tiền bối, hậu bối gần xa - kể cả trước, trong và sau sự kiện này.
Mình luôn có một niềm tin rằng, dù bạn là ai, dù bạn ở đâu, dù bạn làm gì, miễn là bạn cảm thấy vui vẻ và thoải mái với công việc và sự nghiệp mà mình đã chọn, thì bạn đã chọn cho mình một tương lai tốt đẹp hơn rồi. Hãy cố gắng hết khả năng của mình, và bạn sẽ không bao giờ cảm thấy hối tiếc với đời này…
Gửi mọi người hai trang mạng xã hội Facebook chính thức của hai đơn vị tổ chức để có thể cập nhật thông tin về các sự kiện và hoạt động khác được tổ chức xuyên suốt trong năm (Đây là chỗ PR trá hình, tiền của mỗi nơi là 50 ngàn đồng Việt Nam, khỏi cảm ơn) 🤣 :
Hành trình DevOps, Cloud và CI/CD vẫn sẽ còn nối dài với bài viết thứ ba ngay sau đây một tuần nữa với câu chuyện thân quen cùng hai anh bạn, một cũ một mới. Để biết họ là ai thì hẹn gặp lại các bạn ở bài viết tiếp theo. Trân trọng cảm ơn và kính chào! 🚀
Tuấn Anh
Welcome Onboard! - Containerd, Docker, Podman
Xin chào. Đã đến lúc chúng ta vận động một chút rồi. Hãy cùng theo chân mình, bước vào một chuyến hành trình đặc biệt, ở đó, bạn sẽ được gặp gỡ rất nhiều những người bạn đặc biệt, mà có khi bạn chưa từng gặp qua. Are you ready? Welcome Onboard!
Người bạn đầu tiên: Con thuyền Docker
Chà, chắc hẳn bạn đã từng nghe qua về Docker rồi đúng không? Docker là một công cụ giúp bạn có thể đóng gói ứng dụng của mình vào các container, và chạy chúng trên môi trường máy chủ một cách dễ dàng. Điều này giúp cho việc triển khai và quản lý ứng dụng trở nên nhanh chóng và hiệu quả hơn.
Điểm đặc biệt của con thuyền này chính là khả năng chở rất nhiều container khác nhau, cùng với hệ thống mạng lưới kết nối được triển khai trên thuyền (tuy có phần giới hạn hơn so với môi trường máy chủ thực sự). Đây là một nơi thích hợp cho các hoạt động chuyên chở hàng hóa nặng, hoặc là nơi lưu trú tạm thời cho những người muốn khám phá thế giới thông qua mã nguồn chương trình.
Nếu để tìm một điểm để chê bai chiếc thuyền thì chắc sẽ là sự cồng kềnh của nó. Thật sự để làm chủ nó không phải là điều đơn giản, nhưng thật may là bạn không cô đơn - có rất nhiều người từng đi trên con thuyền này sẽ giúp bạn vượt qua những khó khăn đó.
Người bạn thứ hai: Containerd - Thuyền trưởng mới
“Hello world” - Containerd chào mọi người. Đây là một thuyền trưởng mới, một gương mặt mới trong thế giới container. Được phát triển từ Docker, Containerd giúp bạn quản lý các container một cách hiệu quả hơn, đồng thời giúp bạn tận dụng tối đa khả năng của con thuyền Docker. Điểm giống nhau và cũng là khác nhau giữa hai vị thuyền trưởng cũ và mới là yếu tố daemon. Containerd là một dự án CNCF (Cloud Native Computing Foundation), tức là có thể tương thích với các dự án như Kubernetes, Prometheus và CoreDNS.
Containerd có thể chạy như một daemon riêng biệt, hoặc là một phần của Docker. Containerd cũng giúp bạn giảm bớt sự cồng kềnh của Docker, giúp bạn tập trung vào việc chính của mình hơn. Nhưng có 1 điểm containerd không làm được: Khả năng kết nối hệ thống với nhau, vì bản thân Containerd không tự động nhớ đến việc mang lên thuyền bộ công cụ này. Điều này đòi hỏi rất nhiều công sức, thời gian cho việc nghiên cứu cách dùng nó. Mặc cho sự gọn nhẹ, Containerd vẫn không thể thay thế hoàn toàn Docker trong một số hoàn cảnh nhất định…
Người bạn thứ ba: Podman - Những chú hải cẩu tinh nghịch
À, người bạn mới đây rồi… Podman - một công cụ quản lý container mà không cần daemon. Người ta bảo, một nhóm hải cẩu hợp lại với nhau sẽ thành một pod (và trông chúng thật dễ thương 😂 ). Podman giúp bạn có một nơi quản lý container, vừa đơn giản, vừa gọn nhẹ, lại còn dễ sử dụng và an toàn cho mình. Tất nhiên, vì đây là những người bạn khá lạ lẫm - tụi nó là hải cẩu chứ có phải con người hay đồ vật đâu - nên vẫn còn đó nhiều thiếu sót. Nhưng hãy nhìn cái cách đàn hải cẩu thích nghi với môi trường sống chả cần daemon, bạn sẽ thấy nó thật sự quá thông minh cho một vé lên tàu tận hưởng thế giới này rồi.
Làm sao để mời tụi này lên tàu? Làm theo mình ở phần phụ lục nhé!
Thật sự, ngay cả bản thân mình cũng chưa từng quen biết đàn hải cẩu này, nhưng vì tụi nó quá dễ thương và quá là đỉnh cao, nên mình đã quyết định mời tụi nó lên tàu cùng mình. Điều này giúp mình có thêm nhiều trải nghiệm mới, cũng như hiểu rõ hơn về thế giới container. Còn bạn, bạn sẽ chọn ai?
Còn nhiều bạn hơn thế nữa…
Tất nhiên, vẫn còn quá sớm để xem thử có ai còn chưa lên thuyền không… À, tất nhiên còn nhiều lắm.
Nào là LXC này, nào là một số lựa chọn khác như Gradle, HashiCorp Packer, Portainer, Elastic Logstash, LogSpout…
Nhưng việc cho ba người bạn quan trọng nhất lên tàu đã là một bước ngoặt rồi - đây là những người bạn đầu tiên, những người bạn mà mình tin tưởng, và mình chắc chắn rằng, chúng sẽ giúp mình cũng như các bạn có thêm động lực để tìm hiểu hơn về thế giới muôn sắc màu này. Con thuyền đã cập bến đầu tiên, tụi mình xuống thuyền đây. Hẹn gặp lại các bạn ở bến tiếp theo nhé!
Phụ lục Phần 3: Điều khiển Podman
Hướng dẫn dưới đây, dành riêng cho hệ điều hành Ubuntu.
Bạn có thể xem hướng dẫn cho các distro Linux khác tại đây.
# Ubuntu 20.10 and newersudo apt-get update && sudo apt-get upgrade -ysudo apt-get -y install podmanSau khi mời tụi nó lên tàu, chúng ta sẽ khám phá chúng như cái cách chúng ta khám phá Docker vậy.
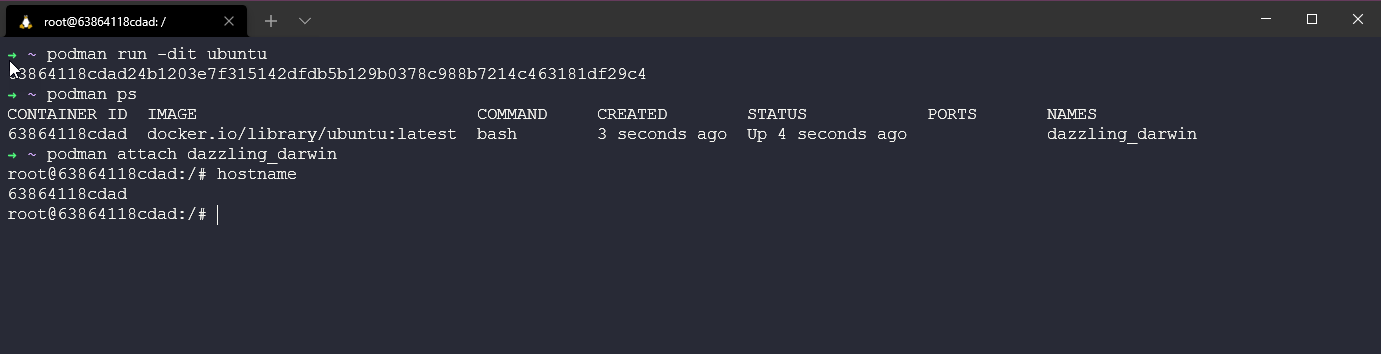
# Gán thuộc tính alias - thay thế các câu lệnh Docker và ứng dụng cho Podmanalias docker=podmanpodman images # Lấy toàn bộ bản ảnh của Podmanpodman run -dit ubuntu # Chạy container từ bản ảnh Ubuntupodman ps # Lấy danh sách containerpodman attach <container_name> # Truy cập vào container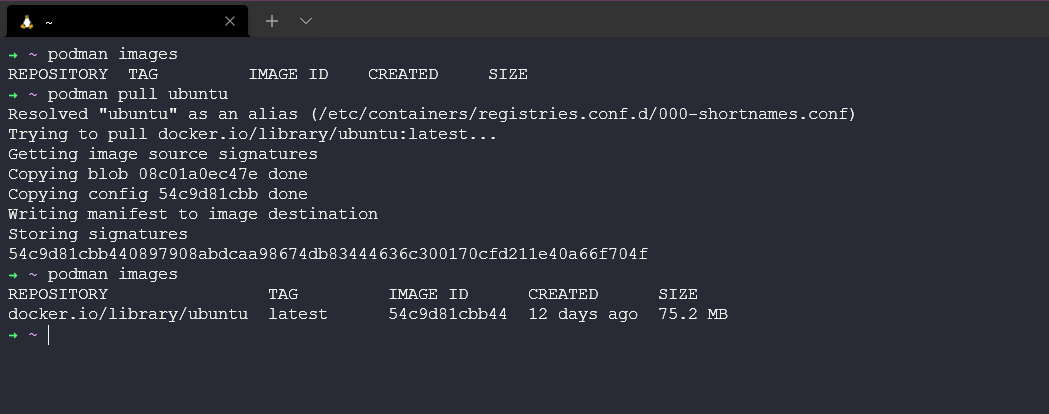
Tổng kết bài viết
Vừa rồi là toàn bộ bài đăng số 4 của series Tech Blog. Mời quý độc giả theo dõi các bài đăng tiếp theo và đóng góp ý kiến cũng trên website này. Trân trọng cảm ơn và kính chào 👋.